I found this post on the blog of a Chinese woman. It is very well written and I think you should all read it.
Xiaoning's Blog
Another good site I saw was Chinacopia. Here is what they had to say about the two scripts.
Chinacopia
I'll let the two sites speak for themselves.
Friday, July 30, 2010
Radish = Dream divination?
I recently had a conversation with a friend about this absurd simplification.
The word radish in Mandarin is 蘿蔔(luó bo). It is a disyllabic word like "butterfly" 蝴蝶 or "camel" 駱駝. Just like any of these words, its characters contain a semantic component, which gives us a hint as to its meaning, and a phonetic component. In this case we have 羅(luó) and 匐(fú). The pronunciation of 蔔 has changed over time and is no longer very phonetic with regards to its phonetic component. Nonetheless, this is the word "radish".
Now in the simplification process, 羅 was simplified to 罗, thus 蘿 became 萝. The character for "dream", 夢(梦 in simplified), looks very similar to this character. The only difference is the addition of a 冖.(※1)
卜(bǔ) is a character that already exists and means "to practise divination; to foretell; to predict". 蔔 was completely replaced by a character that already exists and means something completely different! Now because of this simplification, 卜 has two different sets of meanings. On top of that, 卜 is not a lot more phonetically accurate than 匐.
Anyways, a Taiwanese friend of mine told me that when she saw 萝卜 written while chatting with some Chinese people she completely misunderstood what the person had written.
 Very subtle, huh?
Very subtle, huh?
So the next time you see 萝卜, it's not dream divination, it's radish!
Notes:
※1 A lot of fonts display 夢 with the grass radical 艹, however, this is incorrect. You can see here and here the 說文解字 versions(小篆) of both 草 and 夢. What is on top of 夢 is actually this grapheme, which is a pictograph of sheep horns. Here are the correct versions of them in the traditional script.

 Hey! That's not radish!
Hey! That's not radish!
The word radish in Mandarin is 蘿蔔(luó bo). It is a disyllabic word like "butterfly" 蝴蝶 or "camel" 駱駝. Just like any of these words, its characters contain a semantic component, which gives us a hint as to its meaning, and a phonetic component. In this case we have 羅(luó) and 匐(fú). The pronunciation of 蔔 has changed over time and is no longer very phonetic with regards to its phonetic component. Nonetheless, this is the word "radish".
Now in the simplification process, 羅 was simplified to 罗, thus 蘿 became 萝. The character for "dream", 夢(梦 in simplified), looks very similar to this character. The only difference is the addition of a 冖.(※1)
卜(bǔ) is a character that already exists and means "to practise divination; to foretell; to predict". 蔔 was completely replaced by a character that already exists and means something completely different! Now because of this simplification, 卜 has two different sets of meanings. On top of that, 卜 is not a lot more phonetically accurate than 匐.
Anyways, a Taiwanese friend of mine told me that when she saw 萝卜 written while chatting with some Chinese people she completely misunderstood what the person had written.
 Very subtle, huh?
Very subtle, huh?
So the next time you see 萝卜, it's not dream divination, it's radish!
Notes:
※1 A lot of fonts display 夢 with the grass radical 艹, however, this is incorrect. You can see here and here the 說文解字 versions(小篆) of both 草 and 夢. What is on top of 夢 is actually this grapheme, which is a pictograph of sheep horns. Here are the correct versions of them in the traditional script.

 Hey! That's not radish!
Hey! That's not radish!
More inconsistencies in simplification pt.7
7. 詹

Obviously the Chinese government did not have a problem with this component. There are enough characters to prove it.

If they had changed all of the phonetic components 詹 to 旦 then I would have no problem, but no, they could not. You cannot change 儋 to 但 because it already exists.
A traditional learn can go from from 擔 to 担 much more easily than a simplified learner can go from 担 to 擔.
Changing character components has consequences. It changes the spoken language(with time), it changes the Chinese culture, it removes something that the people of China have been living with for millennia.
Just because the Chinese government simplified some characters and a good portion of Chinese speakers in the world use them does not mean that you have to. You can easily understand simplified characters if you learn traditional ones. You will understand why and how words came to be. You will have a better understanding of the Chinese language than most Chinese people do.

Obviously the Chinese government did not have a problem with this component. There are enough characters to prove it.

If they had changed all of the phonetic components 詹 to 旦 then I would have no problem, but no, they could not. You cannot change 儋 to 但 because it already exists.
A traditional learn can go from from 擔 to 担 much more easily than a simplified learner can go from 担 to 擔.
Changing character components has consequences. It changes the spoken language(with time), it changes the Chinese culture, it removes something that the people of China have been living with for millennia.
Just because the Chinese government simplified some characters and a good portion of Chinese speakers in the world use them does not mean that you have to. You can easily understand simplified characters if you learn traditional ones. You will understand why and how words came to be. You will have a better understanding of the Chinese language than most Chinese people do.
More inconsistencies in simplification pt.6
6. 瞿

Everything looks fine here, no problems that I can see. But wait...there is one simplification...

Why change a phonetic component that is already phonetic when all of the other characters that use it have not been changed?

Everything looks fine here, no problems that I can see. But wait...there is one simplification...

Why change a phonetic component that is already phonetic when all of the other characters that use it have not been changed?
More inconsistencies in simplification pt.5
5. 韱

It takes a few seconds to write, but I find 韱 very beautiful as a character. Apparently the Chinese government didn't have a problem with it either. Or...did they?

Ack! They did it again!! Why?!? Now we have 佥 in the first character used to replace 韱, but 佥 is the simplification of 僉. How did this happen? There are two characters in the traditional script, 簽 and 籤, that were both simplified to 签. Great...now 签 holds two different meanings.
The last two character have had their 韱s replaced by 千. Again, we need some consistency. Right now we have 3 different ways to write this phonetic component in the simplified.
韱佥千 in simplified.
韱 in traditional.
The simplified script seems to be getting less and less simple with further study.

It takes a few seconds to write, but I find 韱 very beautiful as a character. Apparently the Chinese government didn't have a problem with it either. Or...did they?

Ack! They did it again!! Why?!? Now we have 佥 in the first character used to replace 韱, but 佥 is the simplification of 僉. How did this happen? There are two characters in the traditional script, 簽 and 籤, that were both simplified to 签. Great...now 签 holds two different meanings.
The last two character have had their 韱s replaced by 千. Again, we need some consistency. Right now we have 3 different ways to write this phonetic component in the simplified.
韱佥千 in simplified.
韱 in traditional.
The simplified script seems to be getting less and less simple with further study.
More inconsistencies in simplification pt.4
4. 襄

襄 itself is pronounced xiāng. When used as a phonetic component characters are usually pronounced rang, xiang, niang, nang(in descending order of frequency)."Rang" is the most common pronunciation, usually in the 3rd or 2nd tone.

The first pair of characters, 孃 and 娘, are actually variants of each other. We will not count them, I have only added them because in simplified characters they are both 娘.
釀 and 讓 have completely different simplifications. One uses 良 and the other 上.
If all of the characters had used one of these simplifications I would have less of a problem with the simplification process. They have created more differences than similarities. A written language needs to be easy to remember, otherwise it will ultimately fail. The Chinese writing system is one of the world's oldest active, continuously used writing systems. Why change it now?

襄 itself is pronounced xiāng. When used as a phonetic component characters are usually pronounced rang, xiang, niang, nang(in descending order of frequency)."Rang" is the most common pronunciation, usually in the 3rd or 2nd tone.

The first pair of characters, 孃 and 娘, are actually variants of each other. We will not count them, I have only added them because in simplified characters they are both 娘.
釀 and 讓 have completely different simplifications. One uses 良 and the other 上.
If all of the characters had used one of these simplifications I would have less of a problem with the simplification process. They have created more differences than similarities. A written language needs to be easy to remember, otherwise it will ultimately fail. The Chinese writing system is one of the world's oldest active, continuously used writing systems. Why change it now?
More inconsistencies in simplification pt.3
3. 韋

Here we have 韋 and 衛 in 4 characters that have not been simplified.

Here is where things become uneven. The normal simplification for 韋 is 韦. I would have no problem with that...if it were consistent. So most characters containing 韋 have had it simplified to 韦, makes sense. However, look at 衛. A new generic character has been created. 卫 is nothing more than a symbol. It gives no phonetic or semantic hint to help us read or understand it.
It is only has three strokes so it is much quicker to write and I don't find it hard at all to remember. However, it does not follow the same rules as the rest of the 韋 simplifications and as we saw in the first image, some of them were not even simplified! These are not super rare characters that I pulled out of some ancient book, they are characters that are used. I even have a friend who has 暐 in his name.
韋暐衛
韦暐卫 Which do you find easier?

Here we have 韋 and 衛 in 4 characters that have not been simplified.

Here is where things become uneven. The normal simplification for 韋 is 韦. I would have no problem with that...if it were consistent. So most characters containing 韋 have had it simplified to 韦, makes sense. However, look at 衛. A new generic character has been created. 卫 is nothing more than a symbol. It gives no phonetic or semantic hint to help us read or understand it.
It is only has three strokes so it is much quicker to write and I don't find it hard at all to remember. However, it does not follow the same rules as the rest of the 韋 simplifications and as we saw in the first image, some of them were not even simplified! These are not super rare characters that I pulled out of some ancient book, they are characters that are used. I even have a friend who has 暐 in his name.
韋暐衛
韦暐卫 Which do you find easier?
Thursday, July 29, 2010
More inconsistencies in simplification pt.2
This is part 2 of my "More inconsistencies in simplification" post. Again, I did not show all characters that have been affected.
2. 蜀/屬

Here, all of the characters are identical except for the final two, whose radicals have been simplified. I have included a few characters with 屬 since the pronunciation of both components is the same. 屬 is actually made up of 尾 and 蜀. Let's move onto the next image.

So we have a simplification for 屬, which is 属, and one for 蜀, which is 虫.
属 is a generic character that was created to reduce stroke count. Due to this simplification, the semantic and phonetic components have been lost and we are now stuck with a completely new character that we must memorize without any aid.
虫(huǐ/chóng) is a character that already exist. By removing the 罒 and 勹(which was a pictograph of a larva), you are left with only 虫, which also means larva. The pronunciation is now different and no longer aids as a phonetic component.
So again we have an inconsistency in the simplification. Only a handful of the more common characters were simplified to reduce the number of strokes. The phonetic components in these 形聲 have been reduced to nothing more than symbols. Does it really simplify things? I do not believe so.
2. 蜀/屬

Here, all of the characters are identical except for the final two, whose radicals have been simplified. I have included a few characters with 屬 since the pronunciation of both components is the same. 屬 is actually made up of 尾 and 蜀. Let's move onto the next image.

So we have a simplification for 屬, which is 属, and one for 蜀, which is 虫.
属 is a generic character that was created to reduce stroke count. Due to this simplification, the semantic and phonetic components have been lost and we are now stuck with a completely new character that we must memorize without any aid.
虫(huǐ/chóng) is a character that already exist. By removing the 罒 and 勹(which was a pictograph of a larva), you are left with only 虫, which also means larva. The pronunciation is now different and no longer aids as a phonetic component.
So again we have an inconsistency in the simplification. Only a handful of the more common characters were simplified to reduce the number of strokes. The phonetic components in these 形聲 have been reduced to nothing more than symbols. Does it really simplify things? I do not believe so.
Monday, July 26, 2010
More inconsistencies in simplification pt.1
So I enjoyed doing the post on 巤 so much that I'm going to do another one with more examples. Seeing as this post turned out to be rather long, I am going to be breaking it up into seven parts. Each post will contain one of the seven phonetic components that I will be going over; they are 言蜀韋襄韱瞿詹.
I will be showing two sets of characters for each component. The first image will show characters whose traditional (on top) and simplified (on bottom) versions' component are exactly the same. The second image will consist of characters whose components have been changed in simplified or characters that have been completely changed. Click on the images to view the enlarged versions. Let's get started.
1. 言

All of these characters, save for the last two, are exactly the same in both scripts.(※1)(see bottom of post) The second to last character has had 龍 simplified to 龙 but has left 言 unaltered. The last character in this series is rather interesting; it has its radical simplified to 讠 yet it contains another 言 that has not been simplified. How confusing...
So wait, why have we only seen one simplification so far? I thought China simplified the 言 radical? Well, it was simplified, but not everywhere. Take a look at the next image.

So here you see some of the other changes that 言 goes through. Normally 言 is simplified to 讠. However, you can see here that many different changes are occurring.
Let's look at these 3 characters back to back: 狺獄嶽, with each character a component is added(※2). Consistency. The simplified versions: 狺狱岳, one unsimplified 言, one simplified one, and then a completely new character to reduce the number of strokes.
Next look at 諸儲櫧藷蠩. Again we have consistency. In simplified we have 诸储槠藷蠩(※3), the first 3 have simplified 讠s, and the last 2 do not. Why?
The 言 in the character 這 has been replaced with 文 for no reason other than the reduction of strokes.
Lastly, we can see in the second to last character that 言 has been part of a unique simplification based on the shape of the character.
All of this can be rather difficult to remember. When do I simplify? When don't I? The simplification process created many problems such as these. I have only included characters and examples that I was able to think of in the past few days. 言 may have 7 strokes, but it is easy to remember and even to write quickly.
Notes:
※1 The grass component 艸 and the top part of 雚 are written different in both scripts. Click here and here to see examples.
※2 獄 is a 會意(the place where dogs 犭犬 yell 言 at each other = jail).
※3 藷 is not really used anymore, 薯 has taken its place.
I will be showing two sets of characters for each component. The first image will show characters whose traditional (on top) and simplified (on bottom) versions' component are exactly the same. The second image will consist of characters whose components have been changed in simplified or characters that have been completely changed. Click on the images to view the enlarged versions. Let's get started.
1. 言

All of these characters, save for the last two, are exactly the same in both scripts.(※1)(see bottom of post) The second to last character has had 龍 simplified to 龙 but has left 言 unaltered. The last character in this series is rather interesting; it has its radical simplified to 讠 yet it contains another 言 that has not been simplified. How confusing...
So wait, why have we only seen one simplification so far? I thought China simplified the 言 radical? Well, it was simplified, but not everywhere. Take a look at the next image.

So here you see some of the other changes that 言 goes through. Normally 言 is simplified to 讠. However, you can see here that many different changes are occurring.
Let's look at these 3 characters back to back: 狺獄嶽, with each character a component is added(※2). Consistency. The simplified versions: 狺狱岳, one unsimplified 言, one simplified one, and then a completely new character to reduce the number of strokes.
Next look at 諸儲櫧藷蠩. Again we have consistency. In simplified we have 诸储槠藷蠩(※3), the first 3 have simplified 讠s, and the last 2 do not. Why?
The 言 in the character 這 has been replaced with 文 for no reason other than the reduction of strokes.
Lastly, we can see in the second to last character that 言 has been part of a unique simplification based on the shape of the character.
All of this can be rather difficult to remember. When do I simplify? When don't I? The simplification process created many problems such as these. I have only included characters and examples that I was able to think of in the past few days. 言 may have 7 strokes, but it is easy to remember and even to write quickly.
Notes:
※1 The grass component 艸 and the top part of 雚 are written different in both scripts. Click here and here to see examples.
※2 獄 is a 會意(the place where dogs 犭犬 yell 言 at each other = jail).
※3 藷 is not really used anymore, 薯 has taken its place.
Need to know both scripts!
(Here are some traditional characters I thought were pretty.)
(I'm sure you simplified learners are like, "Uhhh, that's ok. I'll stick with simplified thanks!" Haha)
Hi everyone. I have been rather busy this week and haven't had much time to put a lot into a new post. Therefore, I would like to talk to you all about something that has been bothering me quite a bit lately. I'll get right into it. (It begins as a rant but turns into a lesson of sorts)
There are two types of Mandarin learners: those learning simplified characters, and those learning traditional characters. Many choose to learn both scripts, but I am going to categorize those learners with the "traditional learners" and I will tell you why.
From my experience, whenever a traditional learner comes across anything written in simplified characters, he will look at it and say, "Oh, that is 'xxxx' in traditional.".
However, whenever I type anything in traditional to a simplified learner, all I get is, "Uhhh I can't read that." Not even difficult characters either. Most don't even try! I'll give you an example. I wrote this the other day to someone who is learning Mandarin, 「你學中文學了多久了?」Which means, "How long have you been learning Chinese?". There is only one character that differs from the simplified script, 學(学). Now first of all I think from the context one could figure it out, from the shape one can definitely figure it out, and if all else fails...one can look it up. However, the first thing that pops out of his mouth is, "I'm sorry, I can't read traditional characters.".
So why is it that someone learning traditional characters can more than 9 times out of 10 read something written in simplified characters yet it very difficult for simplified learners to do the same with traditional characters? Keep reading.
There are about 80,000+ different characters that have ever been in existence. Obviously most are no longer used, there is a list of 4,808 commonly used characters. University students know around 6,000+ characters. The simplification process changed 2235 characters. So only 2235 of the characters out there were simplified. That means that the rest stayed the same. And of those 2235 characters, a very great majority are characters that have only had their radical simplified. So when a simplified learner says, "I don't want to learn traditional characters, they are too hard to write. Simplified are easier!" This only applies to the 2235 characters that were simplified. The rest have not changed. So basically they are saying, "The 2235 characters that were simplified are easier, but the rest are too difficult to learn." I beg to differ.
TC:強 SC:强 Is this simpler? There is an extra stroke.
Ok, so I won't go into "simpler", but let's go into "simple". If your reason for not wanting to learn traditional characters is that "They are too difficult" or "Simplified are easier" then think again.
Let's take another look at those characters that I wrote at the top of the post. Here they are typed so that you may copy or look them up as you please.
矗戄攫蘸髓麒麟黴囊懿霾巍灌蘗蠢醺霸霹露魔黯嚷嚼壤攘蘑
So they look difficult, huh? Well they are and they aren't. They do however have a lot of strokes, between 20 and 24 each. Why am I showing these to you? Because they are the same in simplified as well. Simplified does not mean simple! There are a LOT more of these, but I just took a few to show you as examples. You may not use all of these words in your life, but a lot of them are rather common. I would say that I have learned about half of these characters from reading them in actual content.
So, now it is a new question... Do you want to learn Chinese characters? If your answer is yes, then I encourage you to learn as much as you can about BOTH scripts because they are BOTH used in all sinophone countries, even China. You may not see traditional on a daily basis in China, but it is there nonetheless. There is plenty of media on the Internet and on TV that is only written in traditional that you need to be able to recognize, and the same goes for simplified.
To sum up my thoughts and my rant: You need to have at least a general knowledge of both of the Chinese scripts. If Chinese people can read traditional characters along with the simplified they were taught in school, then so can you! If the reason you are not learning traditional characters is because they are too "hard", then you probably shouldn't be learning Mandarin at all. A very large number of characters are complicated and have a lot of strokes, this is not only true of traditional characters.
I'd like to end on this little note:
Simplified characters are FASTER to write, but HARDER to read.
Traditional characters are SLOWER to write, but EASIER to read.
Because of the simplifications, many characters now look very similar to one another and make reading harder.

(I'm sure you simplified learners are like, "Uhhh, that's ok. I'll stick with simplified thanks!" Haha)
Hi everyone. I have been rather busy this week and haven't had much time to put a lot into a new post. Therefore, I would like to talk to you all about something that has been bothering me quite a bit lately. I'll get right into it. (It begins as a rant but turns into a lesson of sorts)
There are two types of Mandarin learners: those learning simplified characters, and those learning traditional characters. Many choose to learn both scripts, but I am going to categorize those learners with the "traditional learners" and I will tell you why.
From my experience, whenever a traditional learner comes across anything written in simplified characters, he will look at it and say, "Oh, that is 'xxxx' in traditional.".
However, whenever I type anything in traditional to a simplified learner, all I get is, "Uhhh I can't read that." Not even difficult characters either. Most don't even try! I'll give you an example. I wrote this the other day to someone who is learning Mandarin, 「你學中文學了多久了?」Which means, "How long have you been learning Chinese?". There is only one character that differs from the simplified script, 學(学). Now first of all I think from the context one could figure it out, from the shape one can definitely figure it out, and if all else fails...one can look it up. However, the first thing that pops out of his mouth is, "I'm sorry, I can't read traditional characters.".
So why is it that someone learning traditional characters can more than 9 times out of 10 read something written in simplified characters yet it very difficult for simplified learners to do the same with traditional characters? Keep reading.
There are about 80,000+ different characters that have ever been in existence. Obviously most are no longer used, there is a list of 4,808 commonly used characters. University students know around 6,000+ characters. The simplification process changed 2235 characters. So only 2235 of the characters out there were simplified. That means that the rest stayed the same. And of those 2235 characters, a very great majority are characters that have only had their radical simplified. So when a simplified learner says, "I don't want to learn traditional characters, they are too hard to write. Simplified are easier!" This only applies to the 2235 characters that were simplified. The rest have not changed. So basically they are saying, "The 2235 characters that were simplified are easier, but the rest are too difficult to learn." I beg to differ.
TC:強 SC:强 Is this simpler? There is an extra stroke.
Ok, so I won't go into "simpler", but let's go into "simple". If your reason for not wanting to learn traditional characters is that "They are too difficult" or "Simplified are easier" then think again.
Let's take another look at those characters that I wrote at the top of the post. Here they are typed so that you may copy or look them up as you please.
矗戄攫蘸髓麒麟黴囊懿霾巍灌蘗蠢醺霸霹露魔黯嚷嚼壤攘蘑
So they look difficult, huh? Well they are and they aren't. They do however have a lot of strokes, between 20 and 24 each. Why am I showing these to you? Because they are the same in simplified as well. Simplified does not mean simple! There are a LOT more of these, but I just took a few to show you as examples. You may not use all of these words in your life, but a lot of them are rather common. I would say that I have learned about half of these characters from reading them in actual content.
So, now it is a new question... Do you want to learn Chinese characters? If your answer is yes, then I encourage you to learn as much as you can about BOTH scripts because they are BOTH used in all sinophone countries, even China. You may not see traditional on a daily basis in China, but it is there nonetheless. There is plenty of media on the Internet and on TV that is only written in traditional that you need to be able to recognize, and the same goes for simplified.
To sum up my thoughts and my rant: You need to have at least a general knowledge of both of the Chinese scripts. If Chinese people can read traditional characters along with the simplified they were taught in school, then so can you! If the reason you are not learning traditional characters is because they are too "hard", then you probably shouldn't be learning Mandarin at all. A very large number of characters are complicated and have a lot of strokes, this is not only true of traditional characters.
I'd like to end on this little note:
Simplified characters are FASTER to write, but HARDER to read.
Traditional characters are SLOWER to write, but EASIER to read.
Because of the simplifications, many characters now look very similar to one another and make reading harder.
Sunday, July 18, 2010
New blog URL
The new title and URL are now up. I still need to improve the introduction and layout(badly!!), but at least the main things are out of the way and I can continue posting.
Friday, July 16, 2010
Inconsistencies in simplification
In this post I will be going over an example of some of the inconsistencies in the simplification process. The simplification process was not to be carried out in one bout, but in several smaller reforms. Several attempts had been made, but they were not accepted by the Chinese people; only one was successful. I will go into more details about this in a later post as promised. Basically, radicals were simplified, graphemes were simplified, entire parts were completely removed, phonetic replacements occured, etc. A second reform was attempted, but never accepted by the people and was quickly aborted. Thus, the simplified characters that the People's Republic of China uses today is the result of an incomplete reform with much over-simplification.
You can see some of the characters that would have been put into place through the second reform here.
So, here is one example that I will be focusing on for today. I will probably go over more in the future, we shall see. Let's get started^^
Let us begin with two characters:

巤(liè) and 昔(xí/xī/cuò). We won't worry about the last pronunciation for 昔 as it does not not really come into play here. Let's take a look at a few characters that have 巤 as their phonetic component.

臘(là)、獵(liè)、蠟(là)、鑞(là)、躐(liè)、擸(liè)、鬣(liè)
You'll notice that as a phonetic component, 巤 is almost always pronounced either liè or là. Now let's look at their simplified forms.

腊(là)、猎(liè)、蜡(là)、镴(là)、躐(liè)、擸(liè)、鬣(liè)
As you can see the first three characters have had their phonetic 巤 changed to 昔. The fourth character has only had its radical simplified but has left the phonetic component. The last three characters are the exact same in both scripts.
(Also note the slight differences in the character 巤. The simplified version has a 乂 inside the 口, whereas the traditional version has a 人 instead.)
Now we have some characters with a new phonetic component that is not phonetic at all, and some have not changed at all. This is just one of the inconsistencies that leads to confusion when using simplified characters. In their attempt to "simplify" characters by reducing strokes they have removed one of the main principles of 漢字. Having characters with no phonetic component(or an incorrect one) is not logical. There only exist a few hundred characters these days that are not phono-semantic, the rest follow this pattern.
Now, let us look at one more thing. Seeing that a few of the more commonly used characters that use 巤 as a phonetic component are simplified to 昔, one may think this to be true for all simplifications with 巤. If one were to see 躐, it would be logical to think that its simplification is 踖, however, this is incorrect. These are two different characters with different pronunciations:
躐(liè)(from 巤liè)
踖(jí)(from 昔xí)
While their meanings are similar, they remain two separate characters.
The written Chinese language has been constantly evolving and thus contains many inconsistencies whether in traditional characters or in simplified ones. On top of that, Mandarin is not the only spoken language to use 漢字. What may be phonetic in Mandarin, may not be in one of the other "dialects" of Chinese, and vice versa.
That being said, the simplification process did change some characters' phonetic element to be more accurate: e.g. 嚇→吓. Unfortunately, the number of characters whose phonetic component is now more accurate than it was in the traditional script is very low. Some approximate phonetic components have been used instead, but the emphasis is usually on fewer stroke, ultimately leaving the newly-formed characters without an appropriate phonetic component:
e.g. 聽→听[tīng](the phonetic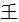 tǐng turned into 斤jīn), 鄰→邻[lín](粦lín changed to 令lìng), 櫃→柜[guì](匱guì changed to 巨jù), 衛→卫[wèi](韋wéi is the phonetic component. Here the entire character has been changed into a newly-created character 卫, creating yet another inconsistency with other characters that use the phonetic 韋wéi), etc.
tǐng turned into 斤jīn), 鄰→邻[lín](粦lín changed to 令lìng), 櫃→柜[guì](匱guì changed to 巨jù), 衛→卫[wèi](韋wéi is the phonetic component. Here the entire character has been changed into a newly-created character 卫, creating yet another inconsistency with other characters that use the phonetic 韋wéi), etc.
In conclusion, fewer strokes does not mean simpler. If you learn the phonetic components, characters become a breeze.
You can see some of the characters that would have been put into place through the second reform here.
So, here is one example that I will be focusing on for today. I will probably go over more in the future, we shall see. Let's get started^^
Let us begin with two characters:

巤(liè) and 昔(xí/xī/cuò). We won't worry about the last pronunciation for 昔 as it does not not really come into play here. Let's take a look at a few characters that have 巤 as their phonetic component.

臘(là)、獵(liè)、蠟(là)、鑞(là)、躐(liè)、擸(liè)、鬣(liè)
You'll notice that as a phonetic component, 巤 is almost always pronounced either liè or là. Now let's look at their simplified forms.

腊(là)、猎(liè)、蜡(là)、镴(là)、躐(liè)、擸(liè)、鬣(liè)
As you can see the first three characters have had their phonetic 巤 changed to 昔. The fourth character has only had its radical simplified but has left the phonetic component. The last three characters are the exact same in both scripts.
(Also note the slight differences in the character 巤. The simplified version has a 乂 inside the 口, whereas the traditional version has a 人 instead.)
Now we have some characters with a new phonetic component that is not phonetic at all, and some have not changed at all. This is just one of the inconsistencies that leads to confusion when using simplified characters. In their attempt to "simplify" characters by reducing strokes they have removed one of the main principles of 漢字. Having characters with no phonetic component(or an incorrect one) is not logical. There only exist a few hundred characters these days that are not phono-semantic, the rest follow this pattern.
Now, let us look at one more thing. Seeing that a few of the more commonly used characters that use 巤 as a phonetic component are simplified to 昔, one may think this to be true for all simplifications with 巤. If one were to see 躐, it would be logical to think that its simplification is 踖, however, this is incorrect. These are two different characters with different pronunciations:
躐(liè)(from 巤liè)
踖(jí)(from 昔xí)
While their meanings are similar, they remain two separate characters.
The written Chinese language has been constantly evolving and thus contains many inconsistencies whether in traditional characters or in simplified ones. On top of that, Mandarin is not the only spoken language to use 漢字. What may be phonetic in Mandarin, may not be in one of the other "dialects" of Chinese, and vice versa.
That being said, the simplification process did change some characters' phonetic element to be more accurate: e.g. 嚇→吓. Unfortunately, the number of characters whose phonetic component is now more accurate than it was in the traditional script is very low. Some approximate phonetic components have been used instead, but the emphasis is usually on fewer stroke, ultimately leaving the newly-formed characters without an appropriate phonetic component:
e.g. 聽→听[tīng](the phonetic
 tǐng turned into 斤jīn), 鄰→邻[lín](粦lín changed to 令lìng), 櫃→柜[guì](匱guì changed to 巨jù), 衛→卫[wèi](韋wéi is the phonetic component. Here the entire character has been changed into a newly-created character 卫, creating yet another inconsistency with other characters that use the phonetic 韋wéi), etc.
tǐng turned into 斤jīn), 鄰→邻[lín](粦lín changed to 令lìng), 櫃→柜[guì](匱guì changed to 巨jù), 衛→卫[wèi](韋wéi is the phonetic component. Here the entire character has been changed into a newly-created character 卫, creating yet another inconsistency with other characters that use the phonetic 韋wéi), etc.In conclusion, fewer strokes does not mean simpler. If you learn the phonetic components, characters become a breeze.
獨 vs. 独
I don't have much time, but I would like to at least make a new post. So here I am going to show you another simplification. This one deals with the removal of a phonetic component to reduce stroke count.
 So here is 獨(dú), which means "alone, independent, single". It is a phono-semantic compound. On the left is
So here is 獨(dú), which means "alone, independent, single". It is a phono-semantic compound. On the left is 犬(quǎn), a pictogram of a dog, here used as the radical. The idea is that dogs are lone animals. On the right is
犬(quǎn), a pictogram of a dog, here used as the radical. The idea is that dogs are lone animals. On the right is  蜀(shǔ, the name of an ancient state). While its pronunciation has changed a lot over time, it still has kept its rhyme. Most characters that have 蜀 as their phonetic value are pronounced "zhu"(usually 3rd tone^^), "du", "shu", or "chu". My next post will include more about pronunciation changes and similarities.
蜀(shǔ, the name of an ancient state). While its pronunciation has changed a lot over time, it still has kept its rhyme. Most characters that have 蜀 as their phonetic value are pronounced "zhu"(usually 3rd tone^^), "du", "shu", or "chu". My next post will include more about pronunciation changes and similarities.
So, onto the simplified version.

So what happened? A part of the phonetic component was removed in order to reduce the number of strokes. This leaves us with 虫(chóng/huǐ, insect), which is not at all a phonetic or semantic component. We are now left with two pictograms and no pronunciation.
So what do you call a phono-semantic compound with no phonetic component?
...I don't know either...
說文解字

Shuowen says: 犬相得而鬬也。从犬蜀聲。羊爲羣,犬爲獨也。一曰北嚻山有獨𤞞獸,如虎,白身,豕鬣,尾如馬。
Translation to come.
 So here is 獨(dú), which means "alone, independent, single". It is a phono-semantic compound. On the left is
So here is 獨(dú), which means "alone, independent, single". It is a phono-semantic compound. On the left is 犬(quǎn), a pictogram of a dog, here used as the radical. The idea is that dogs are lone animals. On the right is
犬(quǎn), a pictogram of a dog, here used as the radical. The idea is that dogs are lone animals. On the right is  蜀(shǔ, the name of an ancient state). While its pronunciation has changed a lot over time, it still has kept its rhyme. Most characters that have 蜀 as their phonetic value are pronounced "zhu"(usually 3rd tone^^), "du", "shu", or "chu". My next post will include more about pronunciation changes and similarities.
蜀(shǔ, the name of an ancient state). While its pronunciation has changed a lot over time, it still has kept its rhyme. Most characters that have 蜀 as their phonetic value are pronounced "zhu"(usually 3rd tone^^), "du", "shu", or "chu". My next post will include more about pronunciation changes and similarities.So, onto the simplified version.

So what happened? A part of the phonetic component was removed in order to reduce the number of strokes. This leaves us with 虫(chóng/huǐ, insect), which is not at all a phonetic or semantic component. We are now left with two pictograms and no pronunciation.
So what do you call a phono-semantic compound with no phonetic component?
...I don't know either...
說文解字

Shuowen says: 犬相得而鬬也。从犬蜀聲。羊爲羣,犬爲獨也。一曰北嚻山有獨𤞞獸,如虎,白身,豕鬣,尾如馬。
Translation to come.
Subscribe to:
Posts (Atom)